Network Transplanting
Quanshi Zhang, Yu Yang, Ying Nian Wu, and Song-Chun Zhu in arXiv:1804.10272, 2018. (PDF)
Abstract
This paper focuses on a novel problem, i.e., transplanting a category-and-task specific neural network to a generic, distributed network, namely a transplant network, without strong supervision. Like building LEGO blocks, incrementally constructing a generic network by asynchronously merging specific neural networks is a crucial bottleneck for deep learning. We aim to teach the generic transplant network a new category by directly transplanting the corresponding network module from a pre-trained network in an un-/weakly-supervised manner, instead of learning from numerous training samples. Network transplanting significantly reduces the cost of learning a universal generic network for all tasks and categories. Most traditional learning/distillation strategies cannot effectively learn for network transplanting, if we do not allow the transplant of new modules to damage the generality of other modules in the transplant network. Thus, we use a new distillation algorithm, namely back-distillation, to overcome specific challenges of network transplanting. Our method without training samples even outperformed the baseline with 100 training samples.
Introduction
![]()
As shown above, we aim to explore a theoretical solution to asynchronously merging specific networks (teachers) into a generic, distributed network (student) in a weakly-supervised or unsupervised manner. The target generic network has a distributed structure, and we call it a transplant network. It consists of three types of modules, i.e., category modules, task modules, and adapters. Each category module extracts general features for a specific category, and each task module is learned for a certain task and is shared by different categories. We can transplant category modules and task modules from specific networks to the generic network. To accomplish network transplanting, we just need to learn a small adapter module to connect each pair of category and task modules. Blue ellipses show modules in specific teacher networks that are used for transplant. Red ellipses indicate new modules added to the transplant network.
We believe that learning via network transplanting will exhibit significant efficiency in representation, learning, and application.
1. Generic, interpretable, & compact representations: A theoretical solution to network transplanting makes an important step towards building a universal, distributed network for all categories and tasks, which is one of ultimate objectives for high-level artificial intelligence. The distributed transplant network has a compact structure, where each category/task module is functionally meaningful and is shared by multiple tasks/categories.
2. Weakly-supervised/unsupervised learning: Transplant of specific networks needs to be conducted with a limited number of training samples or even without any training samples, although the specific network may be learned with strong supervision. It is because it usually more expensive to deliver data than to deliver neural networks in real applications.
3. Asynchronous learning: Unlike learning from scratch, the transplant network needs to incrementally absorb specific networks one-by-one in an asynchronous manner. Such asynchronous learning is quite practical, when the transplant network needs to deal with a large number of categories and tasks. It is because it is difficult to prepare all pre-trained specific networks at the same time. It is also expensive to collect training samples of all tasks and all categories before learning begins.
4. Local transplant vs. global fine-tuning of category and task modules: During network transplanting, we exclusively learn the adapter without fine-tuning the task or category modules. It is because each category/task module is potentially responsible for multiple tasks/categories, and the insertion of a new module should not damage the generality of existing modules. When we have constructed a transplant network with lots of category modules and task modules, we may fine-tune a task module using features of different categories or modify a category module using gradients propagated from multiple task modules to ensure their generality.
5. For application: When the transplant network is comprehensively learned, people can manually connect different pairs of category modules and task modules to accomplish a plenty of different applications, just like building LEGO blocks.
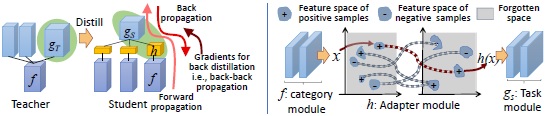
(left) Given a teacher net and a student net, we aim to learn an adapter h via distillation. The teacher net learns a category module f for a single or multiple tasks. The student net contains a task module gS for other categories. As shown in green ellipses, our method distills knowledge from the gT module of a teacher net to the h and gS modules of the student net. The adapter h connects f and gS, so that the task module gS can deal with this new category f. Three red curves show directions of forward propagation, back propagation, and gradient propagation of back distillation. (right) During the transplant, the adapter h learns potential projections between f’s output feature space and gS’s input feature space.

Core challenges & solution1: Most learning strategies are hampered for network transplanting, including 1) directly optimizing the task loss on the top of the network and 2) traditional distillation methods. The core technical challenge is that we can only modify the lower adapter w.r.t. a fixed upper task module gS, without permission to push the fixed upper module towards the lower adapter. When we optimize the task loss, it is quite difficult to learn a lower adapter if the upper gS is fixed. There is vast forgotten space inside the input feature space of the pre-trained gS, and most features of the adapter fall inside the forgotten space. I.e., gS will not pass most information of these features through ReLU layers to the final network output. As a result, the adapter will not receive informative gradients of the loss for learning. Discovering potentially effective input feature spaces from vast forgotten spaces is a necessary but challenging step to learn space projections from f to gS.
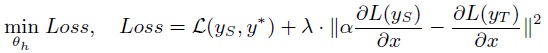
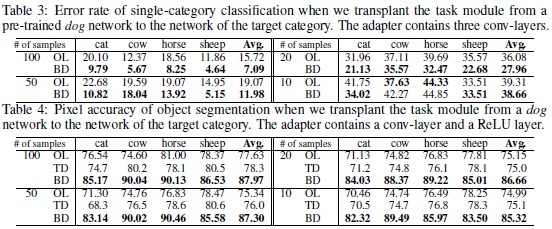
Experimental results
Please contact Dr. Quanshi Zhang, if you have questions.