Interpretable Convolutional Neural Networks
Quanshi Zhang, Ying Nian Wu, and Song-Chun Zhu, in CVPR 2018
You can download the paper and code. Please contact Dr. Quanshi Zhang if you have questions.
Abstract
This paper proposes a method to modify traditional convolutional neural networks (CNNs) into interpretable CNNs, in order to clarify knowledge representations in high conv-layers of CNNs. In an interpretable CNN, each filter in a high conv-layer represents a specific object part. Our interpretable CNNs use the same training data as ordinary CNNs without a need for additional annotations of object parts or textures for supervision. The interpretable CNN automatically assigns each filter in a high conv-layer with an object part during the learning process. We can apply our method to different types of CNNs with various structures. The explicit knowledge representation in an interpretable CNN can help people understand logic inside a CNN, i.e., what patterns are memorized by the CNN for prediction. Experiments have shown that filters in an interpretable CNN are more semantically meaningful than those in traditional CNNs.
Introduction

 .
.
Activation regions of two different convolutional filters in the top conv-layer of an interpretable CNN through different video frames.
.
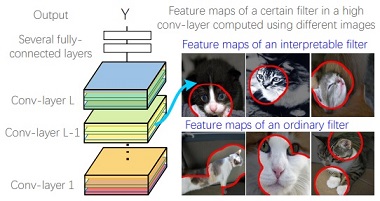
We aim to force each filter in a high conv-layer to represent an object part without using any additional supervision. This figure compares our interpretable CNNs with ordinary CNNs. In a traditional CNN, a high-layer filter may describe a mixture of patterns, i.e., the filter may be activated by both the head part and the leg part of a cat. In contrast, the filter in our interpretable CNN is activated by a single part.
The goal of this study can be summarized as
1. We slightly revise a CNN to improve its interpretability, which can be broadly applied to CNNs with different structures.
2. We learn interpretable filters for a CNN without any additional annotations of object parts or textures for supervision. Training samples are the same as the original CNN.
3. We do not hope the network interpretability greatly affects the discrimination power.
Algorithm
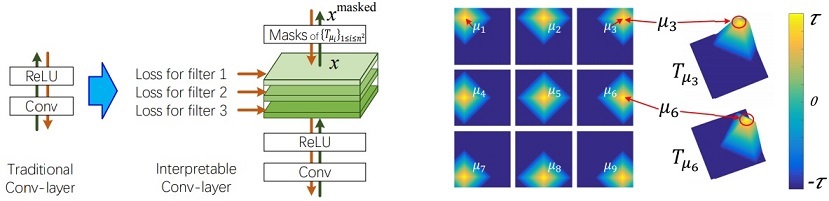
As shown on the left of the above figure, given a high conv-layer in a CNN, we propose a simple yet effective loss for each filter in the conv-layer to push the filter towards the representation of an object part. The loss encourages a low entropy of inter-category activations and a low entropy of spatial distributions of neural activations. I.e., each filter must encode a distinct object part that is exclusively contained by a single object category, and the filter must be activated by a single part of the object, rather than repetitively appear on different object regions. Here, we assume that repetitive shapes on various regions are more prone to describe low-level textures (e.g., colors and edges), instead of high-level parts.
The filter loss is formulated as the minus mutual information between a set of feature maps (X) and a set of pre-defined templates (T). As shown on the right of the above figure, we design (N x N) templates, and each template represents the ideal distribution of activations for the filter’s feature map when the target part mainly triggers each specific unit in the feature map.
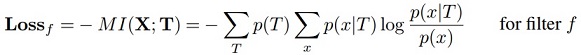
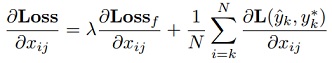
We back propagate gradients of the filter loss to lower layers to update CNN parameters. In fact, we can re-write the filter loss as follows.
![]()
where the first term H(T) denotes a constant prior entropy of part templates. The second term encourages a low conditional entropy of inter-category activations, i.e., a well-learned filter needs to be exclusively activated by a certain category and keep silent on other categories. The third term encourages a low conditional entropy of the spatial distribution of neural activations. I.e., given an image, a well-learned filter should only be activated by a single region of the feature map, instead of repetitively appearing at different locations.
Experiments

The above figure compares feature maps of filters in interpretable CNNs and those in ordinary CNNs. An interpretable filter represents the same object part through different images, whereas an ordinary filter describes a mixture of parts and textures.
 Heat maps for distributions of object parts that are encoded in interpretable filters of a conv-layer.
Heat maps for distributions of object parts that are encoded in interpretable filters of a conv-layer.
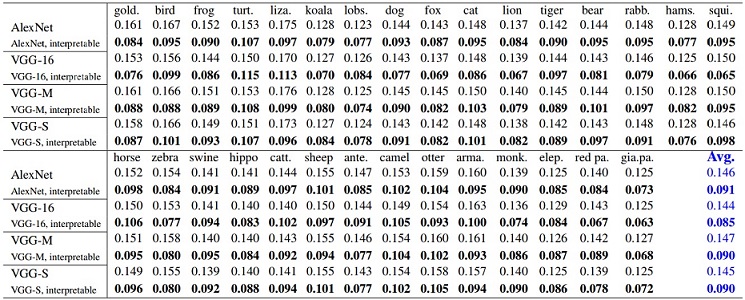
 Location instability of filters in CNNs for single-category classification using the ILSVRC 2013 DET Animal-Part dataset (top), the Pascal-Part dataset (bottom left), and the CUB200-2011 dataset (bottom right). Filters in our interpretable CNNs exhibited significantly lower localization instability than ordinary CNNs in all comparisons
Location instability of filters in CNNs for single-category classification using the ILSVRC 2013 DET Animal-Part dataset (top), the Pascal-Part dataset (bottom left), and the CUB200-2011 dataset (bottom right). Filters in our interpretable CNNs exhibited significantly lower localization instability than ordinary CNNs in all comparisons
.
.
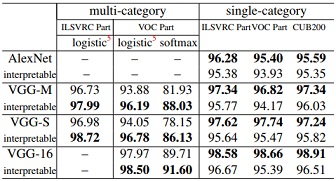
Classification accuracy based on different datasets. In single-category classification, ordinary CNNs performed better, while in multi-category classification, interpretable CNNs exhibited superior performance.