 Quanshi Zhang
Quanshi Zhang ![]()
Associate Professor
国家级海外高层次人才引进计划 ACM China新星奖
John Hopcroft Center for Computer Science, School of electronic information and electrical engineering,
Shanghai Jiao Tong University
Email: zqs1022 [AT] sjtu.edu.cn [知乎] (Curriculum Vita)
News. Serve as an Area Chair in NeurIPS 2024.
招生 Prospective Ph.D., Master, and undergraduate students: I am looking for highly motivated students to work together on the interpretability of neural networks, deep learning theory, and other frontier topics in machine learning and computer vision. Please read “写给学生” and send me your CV and transcripts.
Research Interests My research mainly focuses on explainable AI, including XAI theories, designing interpretable neural networks, and explaining the representation power (e.g., the adversarial robustness and generalization power) of neural networks. In particular, I aim to build up a theoretic system based on game-theoretic interactions, which provides a new perspective to theoretically connect symbolic concepts encoded by a DNN with the DNN’s generalization power and robustness. I also use the game-theoretic interaction to prove the common mechanism shared by many recent heuristic deep-learning methods.





Tutorials & invited talk in explainable AI
VALSE 2022 Keynote [Website]
IJTCS 2022, invited talk [Website]
CVPR 2022 Workshop on the Art of Robustness, Invited talk [Website]
世界人工智能大会(WAIC)可信AI论坛 Panel Discussion [Website]
VALSE 2021 Tutorial on Interpretable Machine Learning [Website]
IJCAI 2021 Tutorial on Theoretically Unifying Conceptual Explanation and Generalization of DNNs [Website][Video]
IJCAI 2020 Tutorial on Trustworthiness of Interpretable Machine Learning [Website] [Video]
PRCV 2020 Tutorial on Robust and Explainable Artificial Intelligence [Website]
ICML 2020 Online Panel Discussion: “Baidu AutoDL: Automated and Interpretable Deep Learning”
A few selected studies
1. This paper (ICLR Oral paper receiving the top-5 score among all oral papers) proves a counterintuitive representation bottleneck shared by all DNNs, i.e., proving which types of interactions (concepts) are easy/hard for a DNN to learn. This paper proves that a DNN is more likely to encode both too simple interactions and too complex interactions, but is less likely to learn interactions of intermediate complexity.

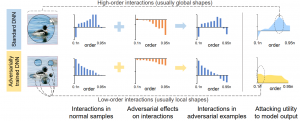
2. This paper (Neurips 2021) provides a unified view to explain different adversarial attacks and defense methods, i.e., the view of multi-order interactions between input variables of DNNs. Based on the multi-order interaction, we discover that adversarial attacks mainly affect high-order interactions to fool the DNN. Furthermore, we find that the robustness of adversarially trained DNNs comes from category-specific low-order interactions. Our findings provide a potential method to unify adversarial perturbations and robustness, which can explain the existing defense methods in a principle way.
3. Interpretable Convolutional Neural Networks. We add additional losses to force each convolutional filter in our interpretable CNN to represent a specific object part. In comparisons, a filter in ordinary CNNs usually represents a mixture of parts and textures. We learn the interpretable CNN without any part annotations for supervision. Clear semantic meanings of middle-layer filters are of significant values in real applications.

 Activation regions of two convolutional filters in the interpretable CNN through different frames.
Activation regions of two convolutional filters in the interpretable CNN through different frames. 
4. Explanatory Graphs for CNNs. We transform traditional CNN representations to interpretable graph representations, i.e., explanatory graphs, in an unsupervised manner. Given a pre-trained CNN, we disentangle feature representations of each convolutional filter into a number of object parts. We use graph nodes to represent the disentangled part components and use graph edges to encode the spatial relationship and co-activation relationship between nodes of different conv-layers. In this way, the explanatory graph encodes the potential knowledge hierarchy hidden inside middle layers of the CNN.

5. This paper (Neurips 2021) proposes a method to visualize the discrimination power of intermediate-layer visual patterns encoded by a DNN. Specifically, we visualize (1) how the DNN gradually learns regional visual patterns in each intermediate layer during the training process, and (2) the effects of the DNN using non-discriminative patterns in low layers to construct disciminative patterns in middle/high layers through the forward propagation. Based on our visualization method, we can quantify knowledge points (i.e., the number of discriminative visual patterns) learned by the DNN to evaluate the representation capacity of the DNN.

Professional Activities
Transactions on Machine Learning Research 担任Action Editor
ACM China SigAI 2024 副秘书长
ACM TURC 2023 SIGAI China Symposium 程序委员会主席
Workshop Co-chair:
VALSE Workshop on Interpretable Visual Models, 2021 (http://valser.org/2021/#/workshopde?id=8)
ICML Workshop on Theoretic Foundation, Criticism, and Application Trend of Explainable AI, 2021 (https://icml2021-xai.github.io/)
CVPR Workshop on Explainable AI, 2019
AAAI Workshop on Network Interpretability for Deep Learning, 2019 (http://networkinterpretability.org)
CVPR Workshop on Language and Vision, 2018 (http://languageandvision.com/)
CVPR Workshop on Language and Vision, 2017 (http://languageandvision.com/2017.html)
Journal Reviewer:
Nature Machine Intelligence, Nature Communications, IEEE Transactions on Pattern Analysis and Machine Intelligence, International Journal of Computer Vision, Journal of Machine Learning Research, IEEE Transactions on Knowledge and Data Engineering, IEEE Transactions on Multimedia, IEEE Transactions on Signal Processing, IEEE Signal Processing Letters, IEEE Robotics and Automation Letters, Neurocomputing