Mining Object Parts from CNNs via Active Question-Answering
Quanshi Zhang, Ruiming Cao, Ying Nian Wu, and Song-Chun Zhu, in CVPR 2017
Abstract
Given a convolutional neural network (CNN) that is pre-trained for object classification, this paper proposes to use active question-answering to weakly-supervised semanticize neural patterns in conv-layers of the CNN and mine part concepts. For each part concept, we mine neural patterns in the pre-trained CNN, which are related to the target part, and use these patterns to construct an And-Or graph (AOG) to represent the target part. The And-Or graph (AOG) represents a four-layer semantic hierarchy of a part as a “white-box” model, which associates different CNN units with different part/sub-part semantics. We start an active human-computer communication to incrementally grow such an AOG on the pre-trained CNN as follows. We allow the computer to actively detect objects, whose neural patterns cannot be explained by the current AOG. Then, the computer asks human about the unexplained objects, and uses the answers to automatically discover certain CNN patterns corresponding to the missing knowledge. We incrementally grow new sub-AOG branches to encode new knowledge discovered during the active-learning process. In experiments, our method exhibited great learning efficiency. Our method used about 1/6 of the part annotations for training, but achieved similar or even much better part-localization performance than fast-RCNN methods on the PASCAL VOC Part dataset and the CUB200-2011 dataset.
Algorithm
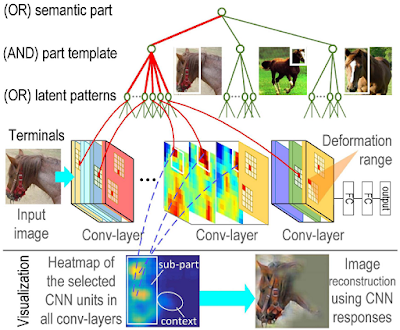
The final goal of this study is to grow an AOG on a pre-trained CNN as a “white-box” model to explain the knowledge hidden in conv-layers of the CNN. The AOG mines latent patterns from conv-layers and associates certain patterns with different semantic parts of objects to represent the semantic hierarchy of objects.
The AOG has four layers, which represents the semantic part, part templates, latent patterns, and CNN units, respectively. In the AOG, we use AND nodes to represent compositional components of a part, and use OR nodes to encode a list of alternative template/deformation candidates for a local region. The top part node (OR node) uses its children to represent a number of template candidates for the part. Each part template (AND node) in the second layer has a number of children as latent patterns to represent its compositional regions (e.g. an eye in the face part). Each latent pattern in the third layer (OR node) naturally corresponds to a certain range of units within a CNN conv-slice. Each CNN unit within this range represents a candidate of geometric deformation of the latent pattern.
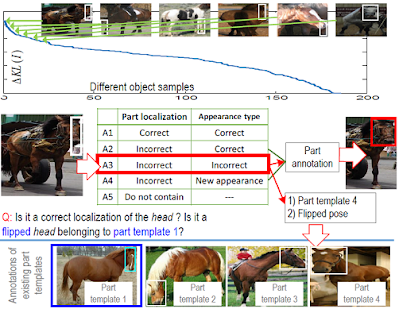
Because the AOG represents the part’s neural patterns with clear semantic hierarchy, we can start an active question-answering (QA) process to incrementally enrich knowledge in each sub-AOG branch, which encodes a specific part template.
During the active QA, we allow the computer itself to discover objects whose neural activations cannot be explained by the current AOG, to rank the priority of different “unknowns”, and to ask human users. Then, the computer uses the answers to grow new sub-AOG branches, which encode new part templates mentioned in the answers. Active QA makes the part knowledge efficiently learned with very limited human supervision.
Experiments
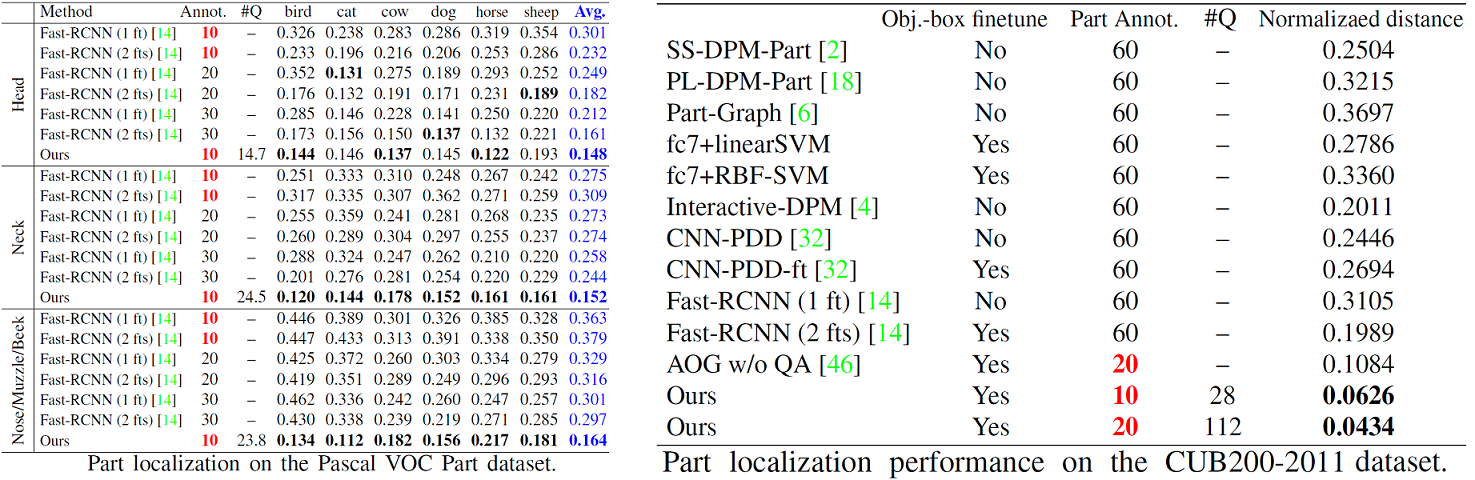
Our method used about 1/6 of the part annotations for training, but achieved similar or even much better part-localization performance than fast-RCNN methods. In addition, the pattern in the AOG usually consistently represent certain part semantics among different images. Compared to the black-box model of a CNN, the AOG representation makes the CNN knowledge more transferable and interpretable.
Part localization performance evaluated based on the metric of the normalized distance.
 Visualization of patterns in the AOG extracted for the head part.
Visualization of patterns in the AOG extracted for the head part.

Performance of localizing animal heads based on AOGs

Please contact Dr. Quanshi Zhang, if you have questions.